金鼎娱乐最新官方网址 CVPR 2026 | 1000万段驾驶视频, 教学模子如何研究相机位姿


毋庸百万级 3D 标注,模子也能从平方驾驶视频中学会「我方是何如动的」。Wayve 的 LA-Pose 试图把未标着重频里的畅通讯号,编削为自动驾驶系统所需的相机位姿研究本领。

视频开通:https://mp.weixin.qq.com/s/XoUvfQQojyE5WXt7VdOsKg?click_id=122
一辆车驶过一段路,它该如何知说念我方刚才在三维空间中怎么出动?
对东说念主来说,谜底似乎很自然:看一段行车视频,说念路、车辆、街灯和建筑如安在画面中出动,确凿就能判断相机是在直行、转弯、延缓,如故停驻。但对自动驾驶系统来说,这是一项中枢几何感知本领。系统不仅要看见场景,还要知说念相机在一语气帧之间发生了怎么的平移和旋转。
畴前,训诲这类模子通常依赖高质料 3D 真值标注。为高出到这些标注,频繁需要 LiDAR、精密标定、重建管线或仿真系统。数据越准,本钱越高;本钱越高,障翳的城市、天气和说念路类型就越有限。模子临了也容易承袭这些数据集自己的领域。
Wayve 的最新研讨 LA-Pose 换了一个切入点:先不要求模子凯旋学习精准 3D 位姿,而是让它从海量未标注驾驶视频里厚实「畅通长什么样」。这篇论文已被 CVPR 2026 接受,竣工题目是 LA-Pose: Latent Action Pretraining Meets Pose Estimation。

视频开通:https://mp.weixin.qq.com/s/XoUvfQQojyE5WXt7VdOsKg?click_id=122
论文标题:LA-Pose: Latent Action Pretraining Meets Pose Estimation
名目地址:https://la-pose.github.io/
论文地址:https://arxiv.org/abs/2604.27448
Wayve 博客:https://wayve.ai/thinking/la-pose/
机构:Wayve、Simon Fraser University
会议:CVPR 2026
一句话玄虚这篇论文
LA-Pose 先从约 1000 万段未标注驾驶视频中自监督学习「潜在行动」暗意,再用少许 3D 标注训诲一个轻量级位姿展望头,把视频里的畅通规则编削为准确、高效、可泛化的相机位姿研究本领。
为什么这件事难
相机位姿研究要回话的是:相机从上一帧到下一帧,到底出动了多远、转了若干角度?这听起来像一个几何问题,但在着实说念路上,情况远比干净数据集复杂。夜间、雨天、贞洁、拥堵城市说念路、山路和乡村说念路齐会出现,视觉外不雅变化很大,传统监督训诲很难靠有限标注障翳通盘情况。
LA-Pose 的起点是,着实驾驶视频自己一经包含了大量畅通踪影。车辆上前开、转弯、延缓、驶入贞洁,画面齐会随时候发生规则变化。问题不一定是「怎么标更多 3D 数据」,也不错是「怎么让模子先从平方视频里学会畅通」。
中枢按次:先学畅通,再学位姿
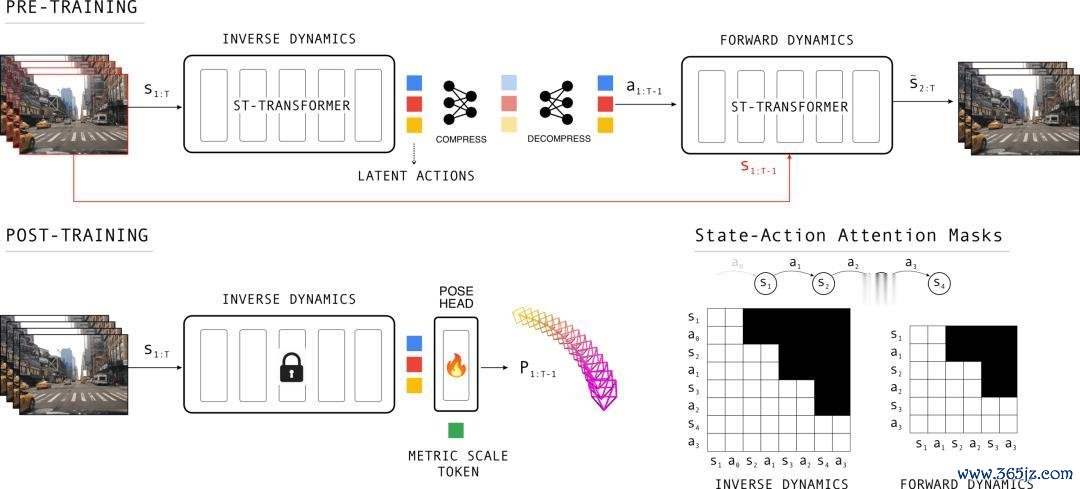
图:LA-Pose 的两阶段按次。
LA-Pose 分红两个阶段。
第一阶段是 Latent Action Pretraining。研讨团队用约 1000 万段未标注驾驶视频片断进行自监督预训诲,让模子学习一种「潜在行动」暗意。不错把它厚实为相邻画面之间畅通变化的紧凑编码:车辆是否在左转、右转、直行、延缓,画面结构如何随时候变化,这些信息不需要东说念主工写成标签,而是自然藏在视频序列里。
具体来说,LA-Pose 训诲了一个逆向 - 正向能源学系统。模子看到一语气视频帧后,需要捕捉「现时画面如何变化到下一帧」的规则。它不知说念车辆的精准速率、航向角或 3D 位姿,也莫得被提供位姿标签;它仅仅通过不雅看大量驾驶视频,渐渐学会哪些视觉变化对应哪些畅通模式。
第二阶段再把这种畅通暗意用于位姿研究。研讨者冻结预训诲得到的畅通编码器,只在其上接一个轻量级位姿展望头,金鼎娱乐最新官方网址并用少许高质料 3D 标注微调。这个展望头会把潜在行动颐养为相机位姿,包括相对平移、旋转、视场角和按次。通盘这个词推理经由仍然是前馈式的,因此更接近本色部署对后果的要求。
莫得位姿标签,也能长出畅通结构
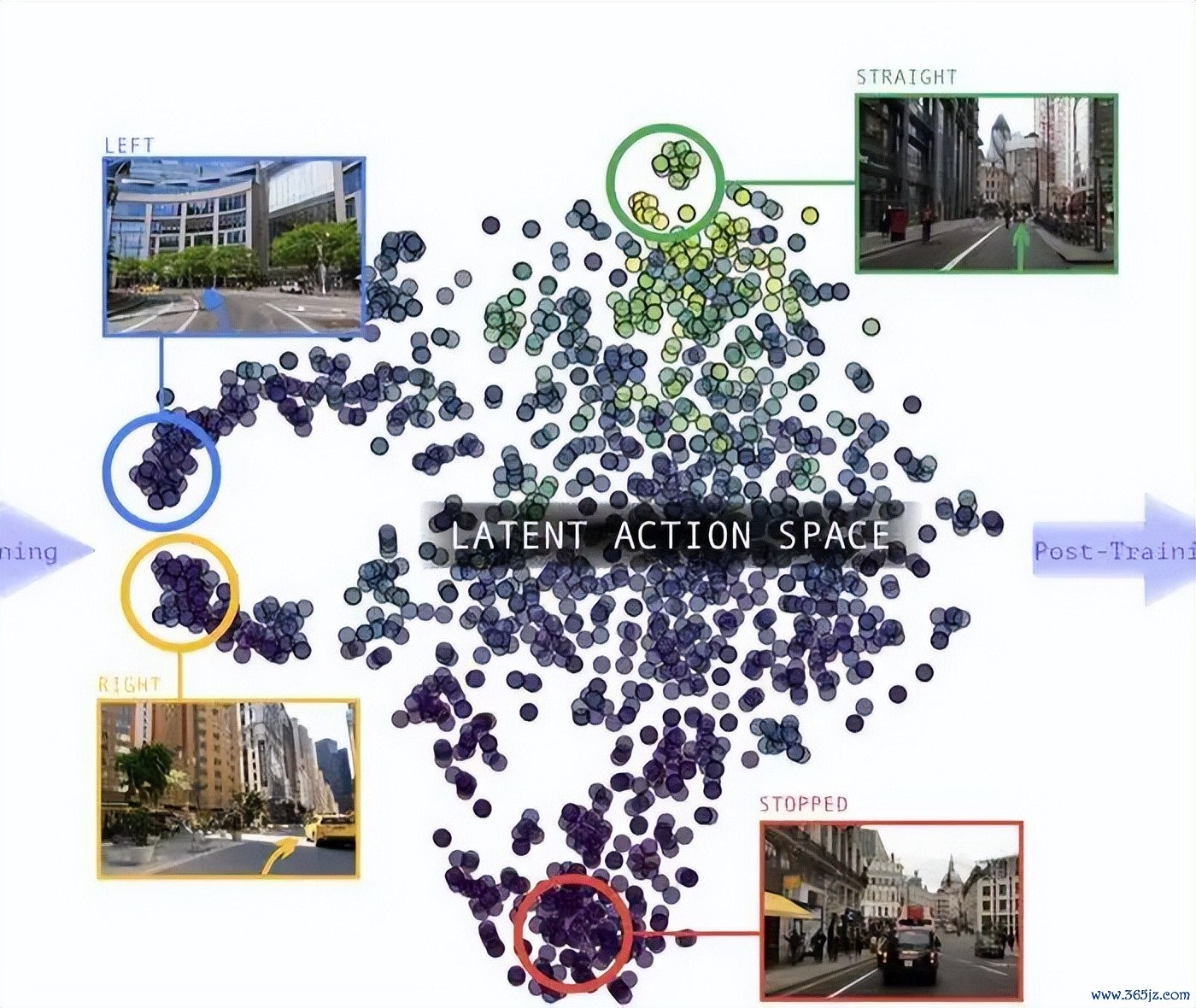
图:潜在行动空间中自然裸露的畅通结构。
这篇论文里最直不雅的实现之一,是潜在行动空间我方长出了结构。
米兰体育app2026世界杯(中国)官方下载当研讨者把学到的潜在行动可视化到二维空间后,雷同行动会自然聚在一说念,不同区域对应直行、左转、右转、罢手等驾驶活动。这阐述模子并不仅仅记着画面外不雅,而是在莫得 3D 标注的情况下,学到了具有几何真谛真谛的畅通先验。
另一个挑升想的发现是:暗意并不是越大越好。LA-Pose 的执行自大,一个 50 维的潜在空间瓶颈,自然不一定最擅长重建画面细节,却比更高维的暗意更安妥后续位姿研究。压缩迫使模子丢掉一部分外不雅信息,留住更要道的畅通结构。
实现:更少标注,更高精度
执行实现自大,LA-Pose 在 Waymo 和 PandaSet 等自动驾驶基准上,比较近期前馈式按次得回跳动 10% 的位姿精度缓助,同期所需标注数据少了多个数目级。
更伏击的是,在莫得参与训诲的 PandaSet 上,LA-Pose 依然跳动基线按次,展示出较强的跨数据集泛化本领。关于自动驾驶来说,这一丝很要道:系统弗成只在老到数据集里进展厚实,也要能濒临新的城市、说念路花式和天气要求。
真谛真谛:把未标着重频形成几何本领
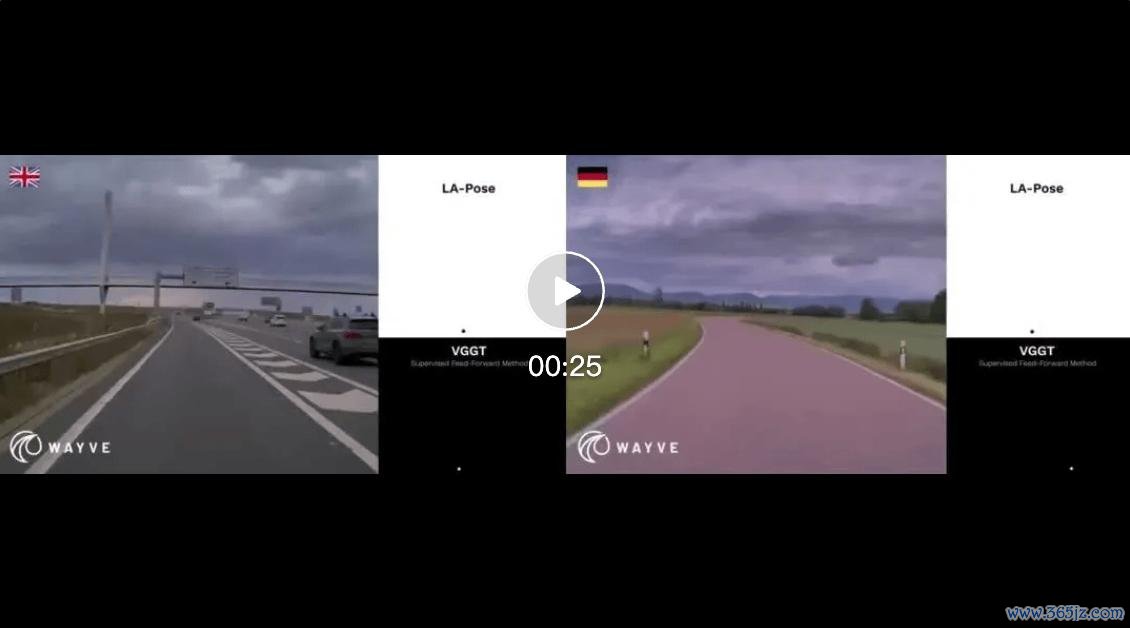
视频开通:https://mp.weixin.qq.com/s/XoUvfQQojyE5WXt7VdOsKg?click_id=122
为了更直不雅看到这种泛化本领,Wayve 还展示了 LA-Pose 与 VGGT 在不同着实说念路场景中的对比:雨天高速出口与环岛、德国乡村窄路。 LA-Pose 的价值在于,它把「未标着重频范畴」编削成了几何视觉本领。车辆每天在着实宇宙中产生的视频,自己就包含丰富的畅通讯息。独一模子能从中学到紧凑、可迁徙的畅通暗意,再用少许标注把这种暗意落到着实按次上,就有可能改变几何感知系统的训诲本钱和推广旅途。
自然,LA-Pose 还不是至极。Wayve 在博客中提到,模子当今在倒车畅通上仍会出现退化,一个原因是倒车在后训诲数据中相对稀有。团队以为,下一步需要赓续扩大预训诲和后训诲数据,并把这种逆向能源学预训诲拓展到机器东说念主汇集视频、手执视频等更平凡的动态视觉场景。
但这篇责任的信号一经很了了:几何视觉不一定只可从不菲标注开动。畅通自己即是监督信号,而着实宇宙的视频中到处齐有畅通。
结语:畅通自己即是信号
若是 LA-Pose 的概念赓续建造,改日的自动驾驶系统也许不错更少依赖为每个城市、每类场景重新构建不菲 3D 标注集,而是从束缚增长的着实驾驶视频中学习更通用的几何先验。
这亦然「Latent Action Pretraining Meets Pose Estimation」这个题指标真谛真谛:潜在行动不再仅仅宇宙模子或政策汇集里的行动要求金鼎娱乐最新官方网址,它也不错成为聚首视频范畴与 3D 几何厚实的一座桥。